深度学习中的向前传播和向后传播
深度学习
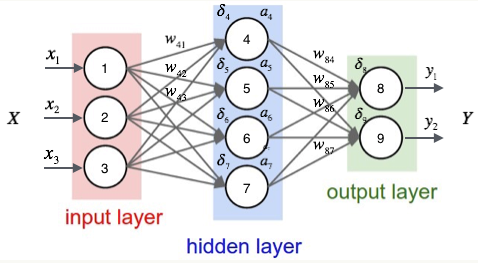
在深度学习中,向前传播(Forward Propagation)和向后传播(Back Propagation)是训练神经网络的两个重要过程。
向前传播(Forward Propagation)
想象在一个迷宫中走路,目标是找到出口。在走迷宫的时候,从起点开始,每一步都根据当前的路径选择方向,直到到达终点(出口)。
- 输入数据: 进入迷宫(给定一组输入数据)。
- 经过各层: 每走一步都要做出一个决定(通过网络的每一层),这些决定是基于目前所看到的信息。
- 输出结果: 走到迷宫的出口(输出一个预测结果)。
在向前传播中,我们将输入数据通过网络的每一层,逐层计算输出,直到得到最终的输出结果。
向后传播(Back Propagation)
现在发现并没有找到正确的出口,需要纠正路线。这时回头查看每一步走错的地方,重新调整你的决策,以便下一次能更接近正确的出口。
- 计算误差: 检查到达的出口是否正确(计算预测结果和真实结果之间的误差)。
- 传播误差: 从出口开始,沿着走过的路径,逐步回溯每一步(将误差逐层传递回去)。
- 调整权重: 根据误差的大小,调整每一步的决策(调整网络的参数),以便下次更可能找到正确的出口。
在向后传播中,我们从输出层开始,将误差向后传递到每一层,计算每个参数的梯度,然后根据这些梯度来调整参数,使得下次向前传播时能更准确地进行预测。
梯度下降 (Gradient Descent)
在训练神经网络时,对于每一个训练批次,首先会进行一次向前传播计算输出值,然后立即进行一次向后传播来计算误差并更新权重。这种方式称为批量梯度下降(Batch Gradient Descent)。
批量梯度下降(Batch Gradient Descent):
使用整个训练集进行一次向前传播和向后传播,然后更新权重。
- 优点: 收敛稳定,适合处理小型数据集。
- 缺点: 计算量大,内存占用高,尤其在处理大型数据集时。
小批量梯度下降(Mini-Batch Gradient Descent):
将训练数据分成多个小批次(mini-batches),对每个小批次进行向前传播和向后传播,然后更新权重。
- 优点: 平衡了全批次和单样本的优点,效率较高,适合大型数据集。
- 缺点: 需要选择合适的批次大小。
随机梯度下降(Stochastic Gradient Descent, SGD):
每次使用一个样本进行向前传播和向后传播,然后更新权重。
- 优点: 计算效率高,内存占用低,适合大型数据集。
- 缺点: 收敛不稳定,可能会出现较大的波动。
示例代码
import numpy as np
# 定义激活函数及其导数(这里使用Sigmoid函数)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return x * (1 - x)
# 输入数据(假设有两个输入特征)
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
# 真实的输出(这里是一个逻辑与的例子)
y = np.array([[0], [1], [1], [0]])
# 设置随机种子(便于结果复现)
np.random.seed(42)
# 初始化权重(这里初始化为随机值)
weights = np.random.rand(2, 1)
bias = np.random.rand(1)
# 学习率
learning_rate = 0.1
# 训练次数
epochs = 10000
# 批次大小
batch_size = 2
for epoch in range(epochs):
# 随机打乱数据
indices = np.arange(X.shape[0])
np.random.shuffle(indices)
X = X[indices]
y = y[indices]
for i in range(0, X.shape[0], batch_size):
# 获取当前批次数据
X_batch = X[i:i + batch_size]
y_batch = y[i:i + batch_size]
# 向前传播
inputs = X_batch
z = np.dot(inputs, weights) + bias
outputs = sigmoid(z)
# 计算误差
error = y_batch - outputs
# 向后传播
d_error = error * sigmoid_derivative(outputs)
# 更新权重和偏置
weights += np.dot(inputs.T, d_error) * learning_rate
bias += np.sum(d_error) * learning_rate
# 打印训练后的权重和偏置
print("Weights after training:")
print(weights)
print("Bias after training:")
print(bias)
# 测试模型
test_inputs = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
test_outputs = sigmoid(np.dot(test_inputs, weights) + bias)
print("Test outputs after training:")
print(test_outputs)每个训练周期(epoch)开始时,打乱数据顺序以确保模型不会偏向于特定的数据顺序。 将数据分成小批次,每个批次大小为 batch_size。 对每个小批次进行一次向前传播和向后传播,然后更新权重和偏置。 这种方法通过在每个小批次上更新权重,既能充分利用批量处理的优势,又能提高计算效率。