深度学习中常见的模型文件格式
llm
深度学习中常见的模型文件格式
在深度学习中,常见的模型文件格式各有其适用场景,选择合适的格式通常取决于所使用的框架、模型类型和部署需求。
.safetensors:
- 用途: .safetensors 是一种专为存储机器学习模型权重而设计的安全文件格式。它通过避免任意代码执行的潜在风险来增强安全性。
- 特点: 这种格式是只读的,确保存储的数据不可篡改或嵌入恶意代码,相较于传统的 .ckpt 格式更安全。
.ckpt:
- 用途: .ckpt 是 TensorFlow 和 PyTorch 中常见的模型检查点(checkpoint)文件格式,用于存储模型的权重、优化器状态以及其他训练状态信息。
- 特点: 这种文件通常是在训练过程中定期保存的,以便于后续恢复训练或推理。.ckpt 文件可以包括整个模型,也可以只包括权重。
.gguf:
- 用途: .gguf 是在特定场景或框架中使用的一种文件格式,可能与生成式模型或特定应用相关,但在标准的深度学习库中并不常见。由于它较为特殊,需要具体的应用上下文来理解。
- 特点: 具体用途可能与生成式对抗网络(GAN)或其他特定应用领域相关,但缺乏标准化的文档或广泛的社区支持。
.bin:
- 用途: .bin 文件是一种通用的二进制文件格式,常用于各种框架中保存模型权重或其他数据。在 Hugging Face Transformers 库中,.bin 文件通常用于存储模型的权重。
- 特点: 这种文件格式不特定于某个框架,更多的是一种用于高效存储和加载数据的通用方式。
.npz .npy:
- 用途: NumPy的文件格式,用于保存多维数组(通常是模型的权重或中间数据)。
- 特点: 二进制格式,高效存储和加载数据。
.pbtxt:
- 用途: TensorFlow的文本格式,保存模型的结构(GraphDef)。
- 特点: 与 .pb 文件类似,但使用人类可读的文本格式。
.model:
- 用途: 通常用于XGBoost、LightGBM等机器学习模型的文件格式。
- 特点: 存储树模型的结构和权重。
.sav:
- 用途: 主要用于保存Scikit-learn模型或Python对象(通过Pickle)。
- 特点: 二进制格式,常用于保存训练好的模型。
.joblib:
- 用途: Scikit-learn常用的模型存储格式,比 .sav 更适合大型对象的压缩和保存。
- 特点: 支持并行化的存储和加载,处理大型numpy数组时性能更优。
.pkl:
- 用途: Python的Pickle文件格式,用于保存Python对象,包括机器学习模型。
- 特点: 灵活但不安全(因为可能会执行任意代码),主要用于本地保存和加载对象。
.mat:
- 用途: MATLAB文件格式,常用于存储矩阵数据和模型。
- 特点: 与MATLAB无缝集成,但也可以在Python中使用 scipy.io 模块读取。
.tar .tar.gz:
- 用途: 用于打包多个文件或整个模型目录(如TensorFlow的SavedModel格式)为压缩文件。
- 特点: 方便模型的分发和存档。
.hkl:
- 用途: Hierarchical Data Format (HDF) 的一种扩展格式,通常用于存储大型多维数组数据。
- 特点: 支持分层存储,适合大规模数据集的高效读取。
.pmml:
- 用途: Predictive Model Markup Language,一种用于描述机器学习模型的XML格式,支持多种机器学习算法。
- 特点: 标准化的格式,支持跨平台和跨语言的模型交换。
.mnn:
- 用途: MNN(Mobile Neural Network)的模型文件格式,适用于移动设备上的深度学习推理。
- 特点: 轻量级且优化的格式,专门为移动平台设计。
.uff (Universal Framework Format):
- 用途: 由NVIDIA开发的,用于保存和导入模型到TensorRT推理引擎中。
- 特点: 适合高性能推理,尤其是在NVIDIA硬件上。
.dnn:
- 用途: 可能指代不同框架的模型文件格式,但一般用于保存深度神经网络模型。
- 特点: 具体用途依赖于上下文,通常与特定的深度学习框架相关。
.h5 .hdf5
- 用途: HDF5 是一种用于存储大量数据的通用文件格式。它在深度学习中广泛用于存储模型的架构、权重、优化器状态以及其他训练配置,尤其在 Keras 和 TensorFlow 中非常常见。
- 特点: 支持大规模数据的高效存储和访问。 可存储复杂的数据结构(例如,模型架构和训练状态)。 跨平台支持,广泛使用。
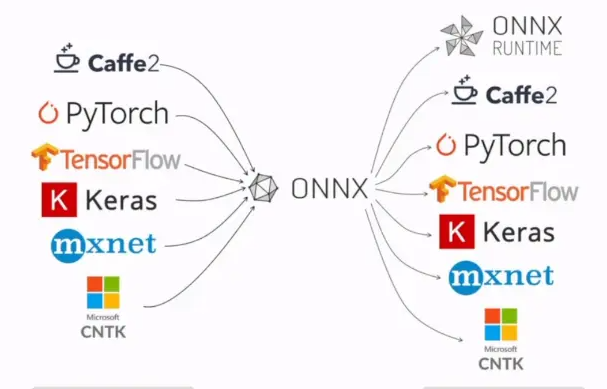
.onnx
- 用途: ONNX(Open Neural Network Exchange)是一种开源文件格式,用于在不同深度学习框架之间转换模型。支持如 PyTorch、TensorFlow、Caffe2 等框架之间的互操作。
- 特点: 跨框架模型转换的标准格式。 广泛支持多种深度学习框架和工具。 适用于模型的推理和部署。
.pb
- 用途: .pb 是 TensorFlow 使用的 Protocol Buffers 文件格式,通常用于保存 TensorFlow 模型的结构图(GraphDef)和权重。
- 特点: 高效的二进制序列化格式。 保存整个计算图和训练好的权重数据。 主要用于 TensorFlow 中的模型部署和推理。
.pth
- 用途: .pth 是 PyTorch 中常用的文件格式,主要用于保存模型的状态字典(state_dict)或整个模型(包括架构和权重)。
- 特点: 常用于保存和加载 PyTorch 模型。 灵活性强,可以保存权重、架构或者整个模型。 易于在训练和推理之间切换。
.pt
- 用途: TorchScript 是 PyTorch 中用于保存经过 JIT(Just-In-Time)编译的模型的文件格式,适用于模型的部署和跨平台使用。
- 特点: 支持将 Python 代码转换为可独立运行的格式。 高性能的序列化和执行,适合部署。 允许在非 Python 环境中使用 PyTorch 模型。
.SavedModel
- 用途: SavedModel 是 TensorFlow 的标准模型格式,包含整个计算图的结构、权重、优化器状态等。通常用于模型的保存和部署。
- 特点: 完整的 TensorFlow 模型保存格式,包含了推理所需的所有信息。 支持导出模型后在不同平台上进行部署。 适用于生产环境的部署。
.params, .json
- 用途: MXNet 使用 .params 文件存储模型的权重,.json 文件存储模型的结构。
- 特点: .params 存储模型参数,.json 描述网络结构。 模型文件通常被分为两个部分,便于模块化和复用。 适合 MXNet 框架用户进行训练和部署。
.caffemodel, .prototxt
- 用途: .caffemodel 文件用于存储 Caffe 模型的权重,而 .prototxt 文件用于定义模型的网络架构。
- 特点: 模型权重和架构分离,便于管理和调试。 早期深度学习模型中广泛使用,尤其在计算机视觉领域。 适合需要高性能推理的应用。
.tflite
- 用途: TensorFlow Lite 的模型文件格式,专为移动设备和嵌入式系统优化。
- 特点: 文件格式经过优化,模型尺寸较小。 适合资源受限的设备,特别是在移动设备上的推理。 提供专门的算子和模型优化工具。
.mlmodel
- 用途: Core ML 是苹果的机器学习框架,.mlmodel 文件格式用于存储模型,主要用于在 iOS 和 macOS 应用中进行机器学习推理。
- 特点: 深度优化,专为苹果设备设计,集成良好。 支持多种机器学习模型(包括深度学习、树模型等)。 方便在 Apple 生态系统中快速部署模型。