
开发指南:使用LangChain智能体创建多模态聊天机器人
llm
在生成式AI领域,智能体已成为创新的关键元素。智能体赋予大型语言模型(LLM)更好的推理能力,并能够执行复杂任务,如与外部数据源接口。 这包括进行Google搜索、调用外部API或生成个性化图像。在我之前的帖子中,我解释了如何使用OpenAI的GPT创建一个个性化的GPT模型,能够生成图像和文本。 本篇文章将向你展示如何开发这种类型的解决方案,让你对所选择的LLM拥有完全的控制权。你可以处理你的专有数据、调用外部API等。 我创建了一个多模态聊天机器人,利用LangChain、ChatGPT、DALL·E 3和Streamlit框架作为其用户界面。 最后,我还将分享我创建的开源仓库,允许你自行探索和部署该聊天机器人。
现实世界中的挑战
这个问题涉及从训练范围之外的现实世界中检索信息。这可能包括执行对专有API的调用或为LLM提供它未经过训练的数据(如文件或图像),然后基于这些数据进行讨论。 我们预期智能体可以将任务分解成更小、更易管理的任务,确定适当的工具及其使用顺序。
智能体在解决这一挑战中的作用
智能体配备了各种工具,包括调用外部API、进行Google搜索或根据特定指令生成图像。这些能力直接解决了我们面临的挑战,提供了全面的解决方案。 然而,在我们探讨解决方案之前,首先必须理解智能体在LangChain框架中的运作。
如图所示,过程在后台展开:当面临用户的任务或查询时,智能体会调用LLM进行推理,实质上将任务分解成较小的中间步骤。 之后,智能体激活适当的工具,将其输出传递给LLM以进行进一步分析。这个推理循环持续进行,直到问题完全解决,并向用户提供解决方案。
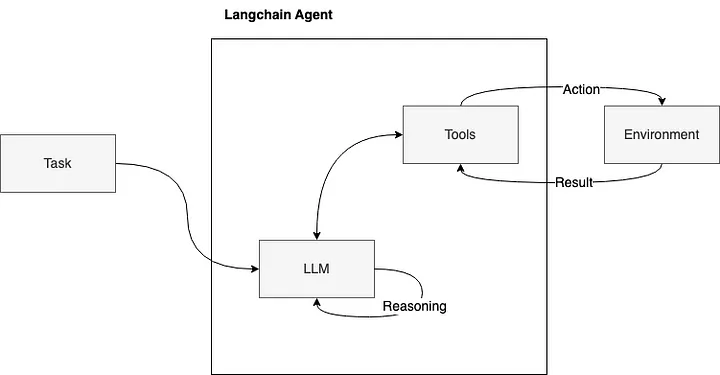
三大主要工具如何提供解决方案
我设计的多模态聊天机器人由一个使用三种工具的智能体支持:
- REST Countries API链:通过调用这个公共API来检索国家信息。
- DALL·E 3图像生成器:根据国家名称生成国家的图像。
- Google搜索工具:用于从网络上获取信息。
我使用Python开发了整个聊天机器人,下面是创建智能体的代码片段:
def create_agent():
tools = [countries_image_generator, get_countries_by_name, google_search]
functions = [convert_to_openai_function(f) for f in tools]
model = ChatOpenAI(model_name="gpt-3.5-turbo-0125").bind(functions=functions)
prompt = ChatPromptTemplate.from_messages([("system", "You are helpful but sassy assistant"),
MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")])
memory = ConversationBufferWindowMemory(return_messages=True, memory_key="chat_history", k=5)
chain = RunnablePassthrough.assign(agent_scratchpad=lambda x: format_to_openai_functions(x["intermediate_steps"])
) | prompt | model | OpenAIFunctionsAgentOutputParser()
agent_executor = AgentExecutor(agent=chain, tools=tools, memory=memory, verbose=True)
return agent_executorLangChain框架为智能体提供了全面的解决方案,无缝集成了各种组件,如提示模板、记忆管理、LLM、输出解析以及在智能体执行器中的这些元素的协调。 create_agent()函数是这一方法的核心,旨在实例化和配置具有特定功能的ChatGPT智能体,集成外部工具和自定义处理管道以处理用户输入和生成响应。
组件解析
-
工具集成: 定义了一组工具,包括countries_image_generator、get_countries_by_name和google_search。这些工具然后被转换为OpenAI函数,使它们可以在ChatGPT的处理管道中被调用。
-
模型配置: 该函数设置了一个ChatGPT模型,特别是“gpt-3.5-turbo-0125”。通过绑定先前转换的OpenAI函数,这个模型在操作期间能够利用这些外部工具。
-
提示模板: 使用一系列预定义消息创建ChatPromptTemplate,包括系统定义的角色和用户输入的占位符,以及用于中间步骤的草稿本。该模板指导对话的流程和结构。
-
记忆管理: 使用ConversationBufferWindowMemory来管理对话历史,存储最近的5条消息(由参数k控制)以提供上下文。此记忆由“chat_history”索引,并配置为返回消息以生成响应。
-
处理管道: 定义了一个处理链,从处理中间步骤的RunnablePassthrough开始,然后通过准备好的提示模板、ChatGPT模型和OpenAIFunctionsAgentOutputParser传递上下文。 这个管道协调数据在智能体中的流动,将模型输出与函数调用集成并解析结果。它使用LangChain表达语言(LCEL),这是一种声明性地将链组合在一起的简便方法。
-
智能体执行器: 函数的核心是创建一个AgentExecutor,它封装了整个智能体及其工具、记忆管理和定义的处理管道。这个执行器运行智能体,处理输入并基于配置生成输出。
在LangChain中创建自定义工具
使用@tool装饰器是在LangChain框架中定义自定义工具的最简单方法。装饰器默认使用函数名作为工具名,可以通过传递字符串作为第一个参数来覆盖。 此外,装饰器使用函数的文档字符串作为工具的描述,因此必须提供文档字符串。你还可以通过传递参数来自定义工具名和JSON参数(见下文第二个工具get_countries_by_name)。
智能体将工具描述作为上下文添加到LLM中,以决定使用哪个工具。选择适当的描述至关重要。
- countries_image_generator工具
@tool
def countries_image_generator(country: str):
"""Call this to get an image of a country"""
res = DallEAPIWrapper(model="dall-e-3").run(
f"You generate image of a country representing the most typical country's characteristics, incorporating its flag. the country is {country}"
)
answer_to_agent = (f"Use this format- Here is an image of {country}: [{country} Image]"
f"url= {res}")
return answer_to_agent我使用了DallEAPIWrapper来调用DALL·E 3模型,并向其提供了具体的指示,说明我希望国家的图像呈现的方式(例如,代表该国家的最典型特征,融入其国旗等)。 然而,我在响应智能体时添加了输出指示,以设定一个包含国家名称和生成的图像 URL 的定义格式。这对于识别智能体的响应是图像而不仅仅是文本至关重要。
- get_countries_by_name工具
def prepare_and_log_request(base_url: str, params: Optional[dict] = None) -> PreparedRequest:
"""Prepare the request and log the full URL."""
req = PreparedRequest()
req.prepare_url(base_url, params)
print(f'\033[92mCalling API: {req.url}\033[0m')
return req
class Params(BaseModel):
fields: Optional[conlist(str, min_items=1, max_items=27)] = Field(
default=None,
description='Fields to filter the output of the request.',
examples=["name", "topLevelDomain", "alpha2Code", "alpha3Code", "currencies", "capital", "callingCodes", "altSpellings", "region", "subregion", "population", "latlng", "demonym", "area", "gini", "timezones", "borders", "nativeName", "numericCode", "languages", "flag", "regionalBlocs", "cioc"]
)
class PathParams(BaseModel):
name: str = Field(..., description='Name of the country')
class RequestModel(BaseModel):
params: Optional[Params] = None
path_params: PathParams
@tool(args_schema=RequestModel)
def get_countries_by_name(path_params: PathParams, params: Optional[Params] = None):
"""Useful for when you need to answer questions about countries. Input should be a fully formed question."""
BASE_URL = f'https://restcountries.com/v3.1/name/{path_params.name}'
effective_params = {"fields": ",".join(params.fields)} if params and params.fields else None
req = prepare_and_log_request(BASE_URL, effective_params)
# Make the request
response = requests.get(req.url)
# Raise an exception if the request was unsuccessful
response.raise_for_status()
return response.json()使用这个特定工具过程中遇到了独特的挑战。第一步是设计一个用于通过名称获取国家信息的REST API参数模型。 我开发了一个Pydantic模型,封装了路径和查询参数来实现这一点。随后,我将这个模型与LangChain工具装饰器集成。
这种方法的价值在于它将参数模型的全面提交给大型语言模型(LLM),包括对每个参数的详细描述,而不仅仅是工具本身的简要概述。 此方法显著增强了LLM根据用户提示精确确定函数正确参数的能力,确保了更准确和高效的交互。
- google_search工具
@tool
def google_search(query: str):
"""Performs a Google search using the provided query string. Choose this tool when you need to find current data"""
return SerpAPIWrapper().run(query)为了通过API在Google上进行搜索,我使用了内置的SerpAPIWrapper。需要注意的是,该工具的操作需要一个API密钥。你可以在我的GitHub Readme中了解如何获取此密钥。
多模态聊天机器人架构
下图展示了多模态聊天机器人系统的结构:
-
提示优化: 初始用户提示和对话历史上下文被传递给LLM(在本例中为ChatGPT),以将提示优化为更精确的查询。
-
思维过程: 智能体将优化后的提示以及任何可选工具传递给LLM进行推理。基于此,决定使用哪种工具。如果在此阶段确定了最终答案,则直接传达给用户。
-
工具调用: 智能体执行选择的工具。
-
观察: 工具生成的输出由智能体发送回LLM进行进一步推理。
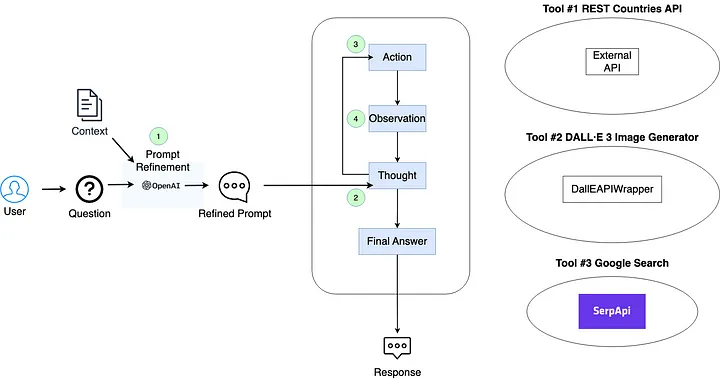
运行多模态聊天机器人
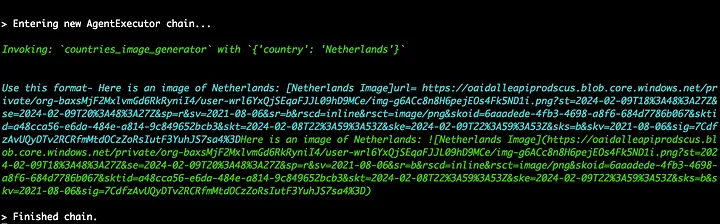
我问的第一个问题是创建荷兰的图像。

很有趣的是,它将自行车描绘成漂浮在水面上,我们还收到了荷兰的图像,捕捉了它的精髓和国旗。
智能体成功调用了“countries_image_generator”工具,输入了必要的参数:国家名称。 随后,我们在蓝色部分观察到了函数的输出:“countries_image_generator”的返回值,展示了由DALL·E 3生成的图像URL。 最后,在绿色部分,我们看到了智能体的最终操作。
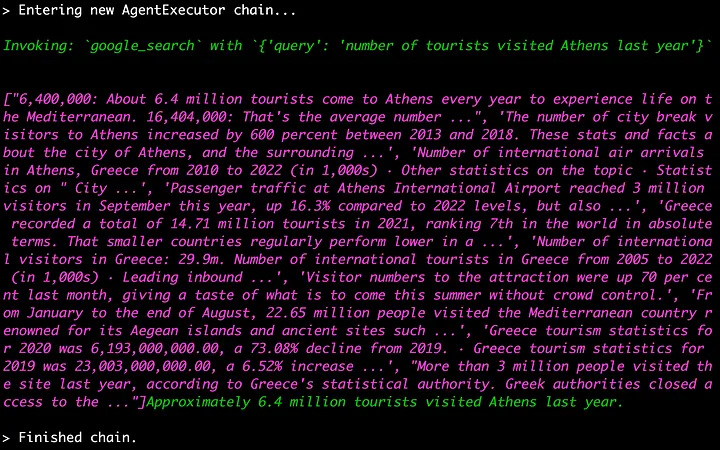
随后,我问了一个问题:“去年有多少游客访问了雅典?” 我收到的回复是有640万游客。由于需要最新的信息,此查询使用了Google搜索工具。 通过使用查询“number of tourists visited Athens last year”进行Google搜索,我们得到了答案。

我接着提出了更多问题:
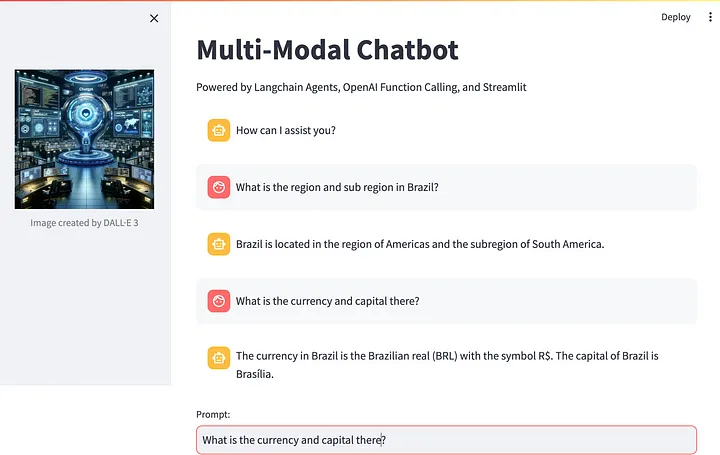
- 巴西的地区和子地区是什么?
- 那里的货币和首都是?
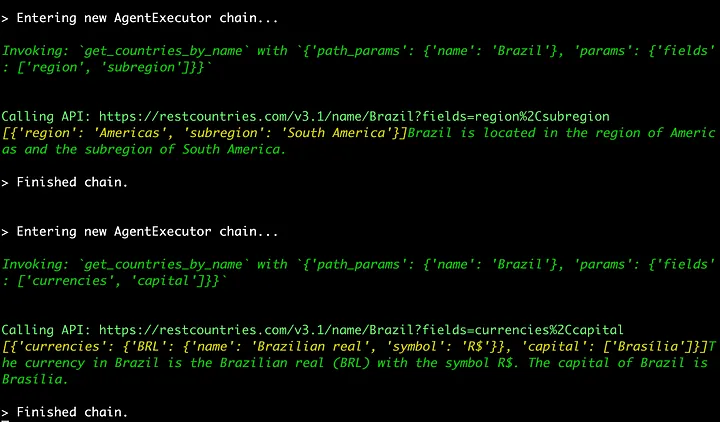
对于这两个问题,使用了get_countries_by_name工具并传入了适当的参数。例如,对于第二个问题,工具被激活并使用了如下参数: get_countries_by_name,参数为 {‘path_params’: {‘name’: ‘Brazil’}, ‘params’: {‘fields’: [‘currencies’, ‘capital’]}}。
此外,这个多模态聊天机器人能够记住之前的互动,如其在后续有关货币和首都的问题中正确推断出国家所展示的能力。
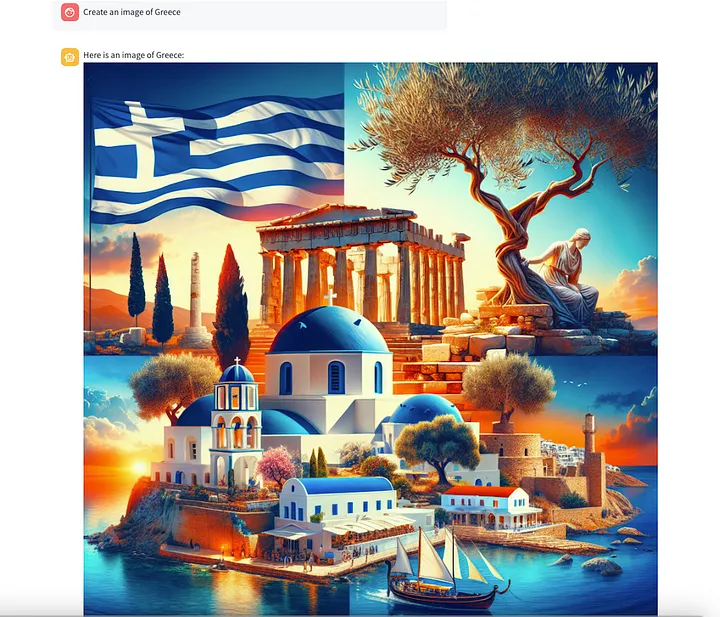
最终,我要求它创建了一张荷兰的图片
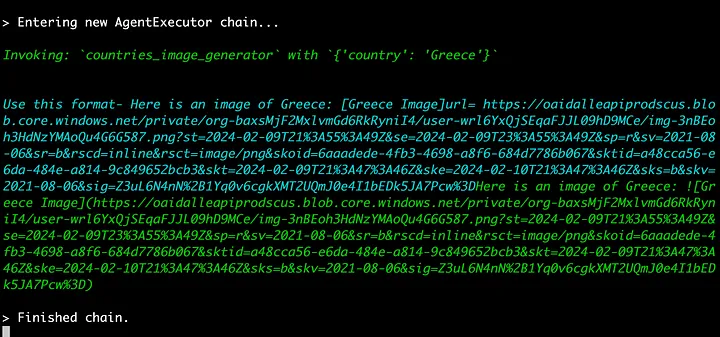
利用智能体解决现实世界问题
你现在应该对智能体在开发强大应用程序中的关键作用有了更好的理解,特别是语言模型如何作为认知引擎发挥作用。 智能体能够智能地决定执行操作的顺序,促进大型语言模型(LLM)与各种外部资源的集成,包括API、专有数据集和互联网搜索等。 我们还展示了LangChain框架在构建多功能聊天机器人中的重要性。这个聊天机器人不仅能够调用外部API和浏览互联网,还可以创建图像,展示其多模态能力。
主要收获:确保选择合适的工具和兼容的 LLM,使其能够进行函数调用,从而根据你的具体需求定制应用程序。